Adding Search to Ghost
Adding Search to Ghost
I wanted to add search functionality to the Ghost CMS. In this post I show the way that I achieved this.
tl;dr I added search with a couple of Python scripts (here and here).
Update (2020-11-27): I’ve moved to a different search implementation, and the search mechanism described in this post has been deprecated.
One feature that is oddly missing from Ghost is a search feature. I thought this rather strange, so I looked around on the Ghost forums to see if there were any known good solutions. I found a few, such as:
These seemed to do the job, but they had two drawbacks from my point of view:
- Both of them require storing the authentication details for the Content API within the theme template, meaning that the content API was essentially open to the entire world to see.
- They seemed to load pages of results from the content API and then use JavaScript libraries such as https://lunrjs.com/ or https://github.com/farzher/fuzzysort which ran client-side. This means the client must load all the contents of every post to find the search results.
That being said, both ghostHunter and ghost-search may be good considerations for someone for whom dealing with the server-side searching may be too daunting.
So I decided to build a simple Python script that I can run as a cron job on the server. This script will periodically connect to the Content API, extract all the posts, and insert them into an SQLite3 database. This database will use the FTS3 extension to allow some reasonable text search. This extraction script will also store the URL to the post, the posts title and the excerpt.
To provide the actual search function, I decided that I’d add a simple Python web server that operating on a separate port to the main site (actually port 9443), which provides an API that the client-side JavaScript can call to get search results.
Populating the Database
The first step to developing the extractor script that would populate the search database was to get the shebang and imports out of the way. I knew that I wanted to have SQLite3, but I also needed the requests library to send HTTP requests to the Content API and the os module to allow me to pass the location of the database file and other settings as environment variables.
#!/usr/bin/env python3 import os import sqlite3 import requests
Now I can load in the settings from the environment. I need to know the location of the database file, the domain that we should connect to (if it’s not blakerain.com) and the Content API key:
DB_PATH = os.environ.get("DB_PATH", "/var/www/ghost-search.db") DOMAIN = os.environ.get("DOMAIN", "blakerain.com") API_KEY = os.environ.get("API_KEY") URL_BASE = f"https://{DOMAIN}/ghost/api/v2/content/posts"
With the variables that contain the settings loaded from the environment, I could connect to the SQLite database and ensure that the FTS3 virtual table has been created. I created five columns in the table:
- The ID of the post. Ghost uses IDs like
5db9aaae56a5780571df0402, so I used a simpleTEXTcolumn to store the ID. - The URL where Ghost will place the post,
- The title of the post,
- The excerpt, which should either be a custom excerpt I write when I create a new post, or the first paragraph of the document. I’ll use the excerpt when I display the list of search results.
- The HTML content of the post, which is what I’ll search through.
# Open the database connection conn = sqlite3.connect(DB_PATH) # Make sure that the posts table is created conn.execute(""" CREATE VIRTUAL TABLE IF NOT EXISTS posts USING fts3( post_id TEXT, url TEXT, title TEXT, excerpt TEXT, html TEXT ); """) # Commit any changes to the database conn.commit()
With the database set up I then moved on to querying the posts from the Content API. You can add API keys to Ghost very simply, by selecting Integrations under the settings panel. Here you can manage current integrations and add new ones:
When you add a new integration, you are presented with two API keys: one for the Content API and another for the Administration API. For this search feature I was only interested in the Content API key:
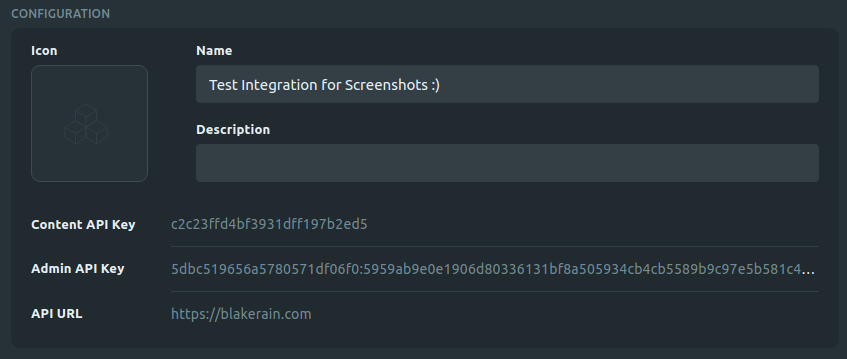
With the API key in hand I could start to make queries to the Content API using Python. To get the content of posts, I needed to make a query to the api/v2/content/posts URL, which would give me back some JSON for a set of posts. This JSON contained all sorts of details that I didn’t really need, so I used the include parameter to select only the required fields for the database (see the documentation here).
Another point to consider is that the Ghost Content API serves the posts as paginated data. So it was necessary to include a page parameter, where the first page starts at one. I put all these parameters together into a simple dictionary that I could pass to the requests module:
PARAMS = { "key": API_KEY, "fields": "id,title,custom_excerpt,html,url", "page": 1 }
I was then able to iterate, calling the API until all the pages had been consumed. This is the simple loop that I ended up with:
# Start on page 1, as you might expect page = 1 while True: print(f"Fetching page {page} from Ghost content API") # Make a request to the Content API to get this page of posts r = requests.get(url = URL_BASE, params = PARAMS) # Decode the response as JSON data = r.json() # Delete any previous entry in our database and insert the new # post data. This makes sure that the search database reflects any # recent changes to any post content. c = conn.cursor() for post in data["posts"]: c.execute("DELETE FROM posts WHERE post_id = ?", (post["id"], )) c.execute("INSERT INTO posts(post_id, url, title, excerpt, html) VALUES(?, ?, ?, ?, ?)", (post["id"], post["url"], post["title"], post["custom_excerpt"], post["html"])) # If the metadata from Ghost indicates there are more pages, then # continue to iterate; otherwise break out of the loop. if data["meta"]["pagination"]["pages"] <= page: print(f"This is the last page") break # Commit any changes to the database conn.commit()
Now I needed to set up the place where the database would reside on the server. As I had installed Ghost into the /var/www/blakerain directory, I figured this would be a good place to store the database, which I imaginatively called ghost-search.db.
With that out of the way I copied the Python script to the server, placing that too in the /var/www/blakerain directory and then added a crontab entry to run the script every hour:
0 * * * * DB_PATH=/var/www/blakerain/ghost-search.db API_KEY=... /var/www/blakerain/populate-db.py
Confident that everything would magically work I moved on to the search API.
Executing Search Queries
In order for the FTS3 table to be searched by some client-side JavaScript I decided to create another Python script that would use Flask-RESTful to provide an API. This API would accept a single search term, query the database, and then return any results as JSON. The client-side JavaScript could then use this JSON to render the search results.
As before, the first step was to get the shebang and imports out of the way. I knew that I needed the Flask imports, along with the os module to get the database path from an environment variable and sqlite3 so I could open connections to the database:
#!/usr/bin/env python3 import os import sqlite3 from flask import Flask from flask_restful import Api, Resource, reqparse
As with the previous script, I was going to pass the path to the database file in the DB_PATH environment variable, so I needed to extract that, falling back to a sane location if it was undefined:
DB_PATH = os.environ.get("DB_PATH", "/var/www/ghost-search.db")
Next I created the Flask application and the API instance to which I would add my API resources:
app = Flask(__name__) api = Api(app)
With that out of the way I could define the search resource. This resource, cleverly named Search, would accept a GET request containing the search term. It would then create a connection to the database, execute an FTS query on the virtual posts table created by the extractor script and return the results.
class Search(Resource): def get(self, term): print(f"Search term: '{term}'") # Create the connection to the database conn = sqlite3.connect(DB_PATH) c = conn.cursor() # Query the database and add the results to an array results = [] for row in c.execute("SELECT post_id, url, title, excerpt FROM posts WHERE html MATCH ?", (term,)): results.append({ "id": row[0], "url": row[1], "title": row[2], "excerpt": row[3] }) # Return the array as a response, which will be encoded as JSON return results, 200
Just a little note here about the SQLite3 database connection. Python insists that a database connection can only be used by the thread that created it. For this reason I create a database connection on every request.
With this script finished I needed to get two more things set up on the server:
- I needed a way to run the script in a managed way, and
- NGINX needed to know to proxy the API under the blakerain.com domain.
The first step was simple. I added a script on the server under /etc/systemd/system called simple-search.service that contained a service definition for the search API:
[Unit] Description=Ghost simple search server After=network.target [Service] Environment="DB_PATH=/var/www/blakerain/ghost-search.db" ExecStart="/var/www/blakerain/simple-search.py" [Install] WantedBy=multi-user.target
After the service definition was created I was able to tell systemd to reload the daemon configurations and then enable and start the service:
sudo systemctl daemon-reload sudo systemctl enable simple-search sudo systemctl start simple-search
I checked to make sure that the service was running by making a call to port 5000, and then also checking to make sure that the log message showed up in journald:
$ curl http://localhost:5000/search/not+a+search+term [] $ journalctl -eu simple-search Oct 27 16:07:12 ip-?-?-? simple-search.py[11080]: 127.0.0.1 - - [27/Oct/2019 16:07:12] "GET /search/not+a+search+term HTTP/1.1" 200 -
Now that I new the API service was in place I needed to configure NGINX so that it would proxy HTTPS from port 9443 to the service port 5000. This meant adding a file in the directory /etc/nginx/sites-available that contained the configuration for NGINX. This file also needed to contain the links to the SSL certificate that Let’s Encrypt had set up when Ghost was being installed. Checking in /etc/letsencrypt showed a directory called blakerain.com that contain the certificate chain and the private key. I could use the default SSL settings from /etc/nginx/snippets/ssl-params.conf for the rest.
server {
listen 9443 ssl http2;
listen [::]:9443 ssl http2;
server_name blakerain.com;
root /var/www/blakerain/system/nginx_root;
ssl_certificate /etc/letsencrypt/blakerain.com/fullchain.cer;
ssl_certificate_key /etc/letsencrypt/blakerain.com/blakerain.com.key;
include /etc/nginx/snippets/ssl-params.conf;
location / {
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header Host $http_host;
proxy_pass http://127.0.0.1:5000;
add_header 'Access-Control-Allow-Origin' '*';
}
client_max_body_size 1m;
}
Note that the configuration adds the Access-Control-Allow-Origin header value of *. This will become more relevant later on.
To get NGINX to recognize the new site I created a symbol link from the file in /etc/nginx/site-available to /etc/nginx/sites-enabled and then restarted the NGINX server:
ln -s /etc/nginx/sites-available/simple-search-ssl.conf /etc/nginx/sites-enabled sudo systemctl restart nginx
Now I needed to be able to check that this all worked, so I went into AWS and modified the Security Group for the network adapter attached to the instance on which the site is running to include the 9443 port:
| Port | Source CIDR | Description |
|---|---|---|
| tcp/22 | MY-IP/32 | Let me SSH into the server |
| tcp/80 | 0.0.0.0/0 | Allow HTTP over IPv4 |
| tcp/80 | ::/0 | Allow HTTP over IPv6 |
| tcp/443 | 0.0.0.0/0 | Allow HTTPS over IPv4 |
| tcp/443 | ::/0 | Allow HTTPS over IPv6 |
| tcp/9443 | 0.0.0.0/0 | Allow search API over IPv4 (new) |
| tcp/9443 | ::/0 | Allow search API over IPv6 (new) |
This allows TCP connections on port 9443 to make their way to the instance. Hopefully NGINX will then proxy the HTTP (and HTTP2) requests to the Python search API. I checked this by making a similar call using curl as I had before, only this time on my local machine just to check the AWS SG configuration:
curl https://blakerain.com:9443/search/not+a+search []
Client-Side Search
Now that the back-end of the search seems to be working okay (although I’ve not seen it bring through any results yet), I started out on the client side. I knew that I wanted two things:
- A small search box at the top of the site in the navigation, and
- A search page that would fetch and display the actual search results.
The first step was adding in the HTML for the search. This meant modifying the theme I was using. I am using a modified version of the Casper theme, so the contents of the navigation bar are found in the partials/site-nav.hbs file. I added in a small <form> element for the search:
<div class="search-bar"> <form name="search" action="/search" method="GET"> <input type="text" name="search_term" placeholder="Search" /> <button type="submit"> <i class="fas fa-search"></i> </button> </form> </div>
As you can see, the action of the form is to submit a GET requests to the /search path. This would use URL encoding for the form elements, which would mean that a search term such as “what now” would turn into:
https://blakerain.com/search?search_term=what+now
I also added some CSS to the assets/css/screen.css file that would apply some styling to the form. As I’m pretty lazy and bad at CSS I used flexbox to make sure that the input field and the button are placed adjacent to each other horizontally. I also applied some light styling to both the form elements to make sure they fitted in with the theme, but I didn’t do anything especially grand.
.search-bar { margin-right: 1rem; } .search-bar form { display: flex; } .search-bar input { flex-grow: 1; background: none; outline: none; color: rgba(255, 255, 255, 0.75); border: 1px solid #7f92a6; padding: 5px; border-radius: 5px; margin-right: 0.5rem; } .search-bar button { flex-grow: 0; color: rgba(255, 255, 255, 0.75); border: 1px solid #7f92a6; border-radius: 5px; background: none; width: 31px; height: 28px; }
With that in place I needed to create the search page. Now Ghost already provides a simple way of doing this, so I went into the Pages section of the administration interface and added a new page called Search Results. I changed the page URL in the settings to be search, which should correspond to the location to which the search results are posted:
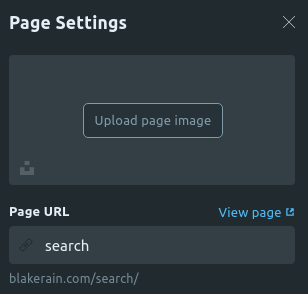
With this page added I then tested the form, and it happily navigated me to the new search page and the form contents were in the URL. To create the contents of the search page I added them directly into the page editor in Ghost by selecting HTML when I added a new card in the editor:

With that open I could add the HTML for the larger search box and the JavaScript that makes the call to the API. The JavaScript to make the API call was fairly simple. The Ghost theme includes jQuery already, so I could make use of that rather than use XMLHttpRequest directly. First I needed to extract the search term from the URL. The form submits the search as URL encoded parameters, so I can extract the search_term using regular expressions and then massage the string somewhat to decode it:
var term = /\?search_term=(.*)/ .exec(window.location.search)[1] .replace(/\+/g, " ") .trim();
Once I have the search term I can make a call to the API on port 9443 to get the search results. I then pass the search results to a function called render_results that will process the returned JSON and use jQuery to add in some rows:
$.getJSON("https://blakerain.com:9443/search/" + term, function (results) { if (results.length === 0) { no_results(); } else { render_results(results); } });
I shan’t belabor with the JavaScript that generates the content, as that’s not especially interesting and I intend to replace it with something better at some point.
A couple of things I will note, however:
- Ghost lets you add some injection for specific pages, which is where I added some specific styling for the result HTML.
- Be aware that if the search API doesn’t specify an
Access-Control-Allow-Originthen the web browser will refuse to make the request, even though the domain is actually the same.
Conclusion
In conclusion it seems that adding a separate search facility to Ghost was a lot easier than I was worried it might be. I had originally concerned myself with modifying Ghost itself (I’ve no idea what JAMstack is or how Ghost actually works). After seeing the other implementations I was inspired to take this approach, which seems to have worked quite well. The search is fairly fast, and will probably remain so for the foreseeable future.
I did also consider connecting to MySQL and reading the post contents from that. Having looked at the schema I thought that this seemed like it might be a lot harder than I originally anticipated. Ghost stores the content of the posts as JSON, but the Content API returns HTML. Moreover, the Content API also respects whether a post is actually publicly visible or not.
For now, you can find the Python scripts and the configuration files used on the server in the GitHub page for this blog and it’s theme:
https://github.com/HalfWayMan/blakerain.com
There you will find the sources such as simple-search.py.
Future Improvements
There are a few things that I want to add to the search to improve it somewhat:
- Update the API to use a
POSTmethod and encode the search term in the HTTP body rather than using a URL. - Add some rate limits to the API, which is something that I may be able to do in the NGINX configuration.
- Improve the HTML and JavaScript in the search page by using React to create the interface.
- Extract the content from the post rather than storing the raw HTML in the database.
When I get round to adding these improvements I will be sure to describe them in another post.