Updated Site Search
Updated Site Search
In this post we look at an updated implementation of the site search feature.
I decided to re-visit the search functionality that I had added to this site to provide a slightly better search mechanism. I had three objectives that I wanted to achieve:
- The new search should happen interactively in a pop-up,
- I wanted the process to be simpler, removing the secondary search server, and
- The results should be highlighted when a page is selected.
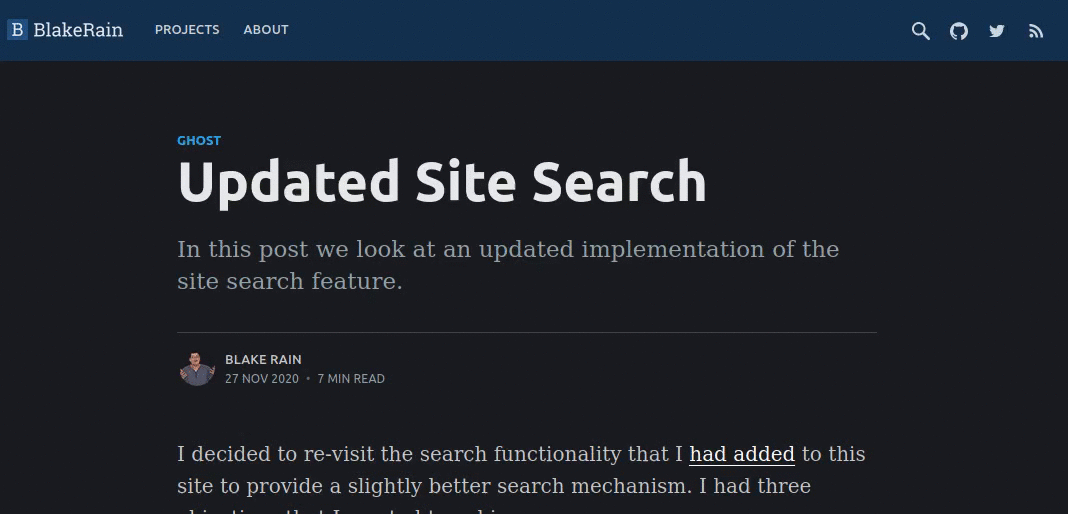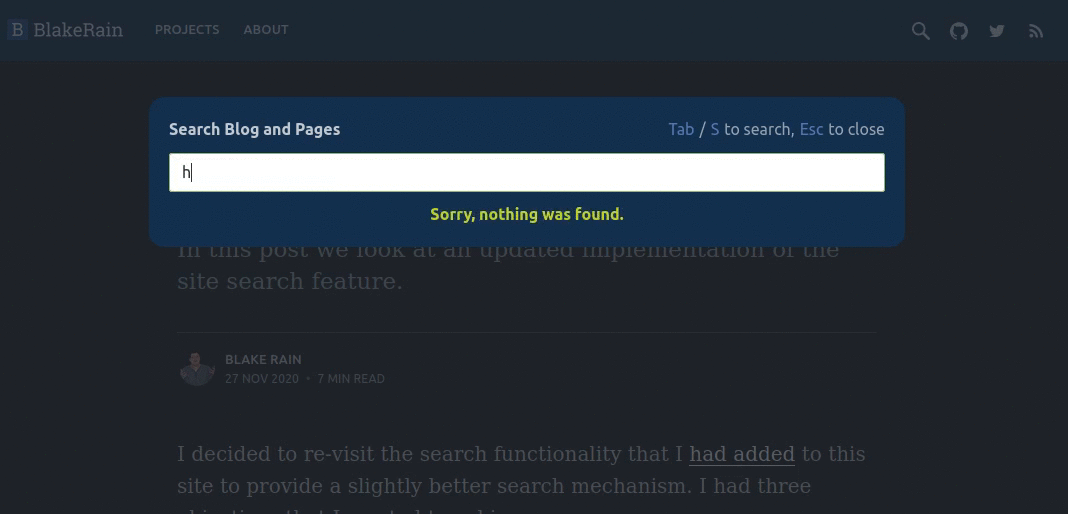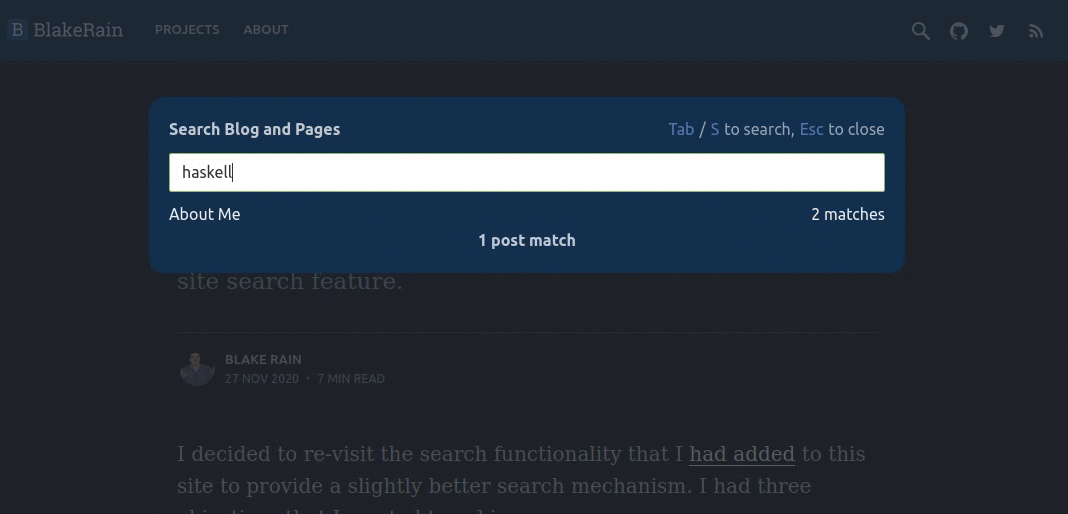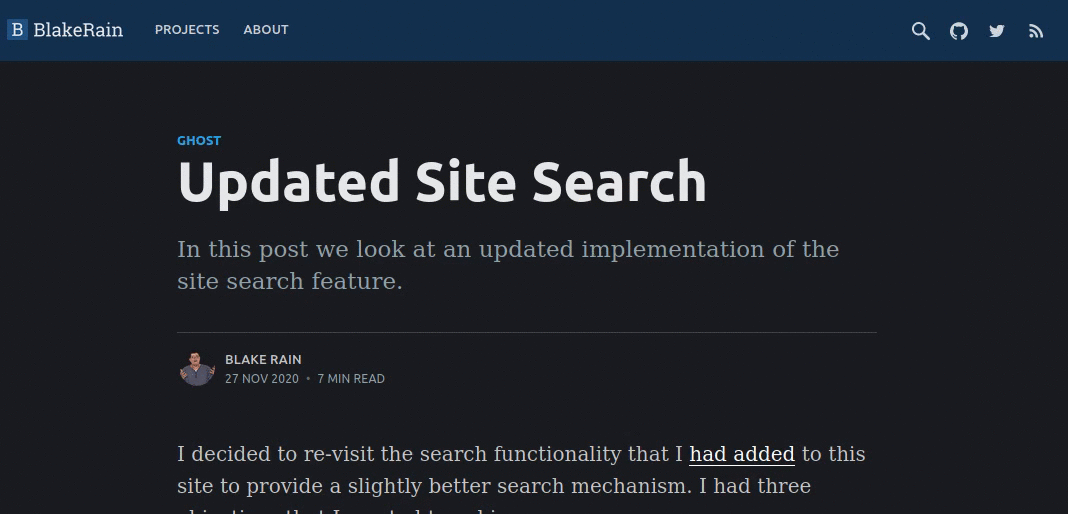
The search function that I added is triggered either by clicking on the search icon in the top-right of the navigation bar or by pressing either the Tab or s key. Text entered into the displayed search pop-up is immediately applied to the search system and the results update dynamically.
The new search comprises two main components: a front-end interface and a back-end. The back-end runs as a GitHub Action, which generates the search data from the site contents. The front-end is a small amount of React code that is built along with the rest of the theme. The front-end provides the interactive search.
In this post I go into some detail of how the search is implemented. All the source code is available in the GitHub repository for this blog.
Using a Prefix Tree
One of my goals for the new search is that it should be interactive, and quite fast. That means it must quickly give the user reasonably useful results. Moreover, as I wanted to simplify the implementation, I would like to maintain very few dependencies.
I decided that a quick way to achieve this was to use a prefix tree. According to Wikipedia:
In computer science, a trie, also called digital tree or prefix tree, is a kind of search tree—an ordered tree data structure used to store a dynamic set or associative array where the keys are usually strings.
In this search tree I wanted to be able to link any recognized word with an occurrence set: describing the number of times the word appears in each post. For example, consider the following five words and their occurrences in two documents:
| Term | Document 1 | Document 2 |
|---|---|---|
| ben | 1 | 2 |
| bell | 0 | 4 |
| bin | 5 | 0 |
| cat | 8 | 0 |
| car | 0 | 2 |
We then assemble this data into a search tree. Each node of the search tree can represent a word we recognize, and the edges of the tree represent the letters:
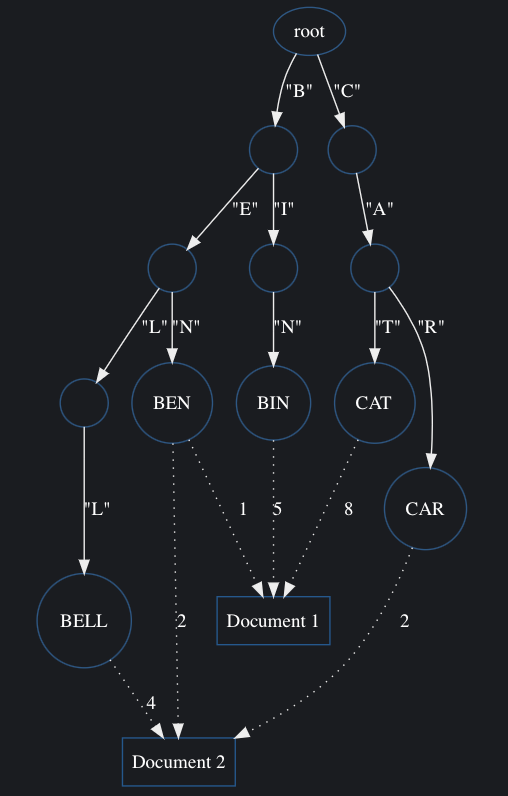
Typically the power of a trie like this is in being able to find all the matches for a given prefix. For example, given the input sequence "be" we can infer that this is either: "ben" or "bell". For this reason, ties can often be used when implementing prefix-oriented searches such as auto-complete in text editors.
I decided to leverage this for the search mechanism. When an input sequence like "be" is entered, we descend the tree and tally all occurrences for each leaf we encounter. First we want to take a search term and walk along the tree, following the edge that corresponds to each character in the search term. Once we have found the node for the last letter of the search term, we move on to searching for all occurrences.
find_string(prefix):
node = root
for ch in prefix:
if node contains ch:
node = node[ch]
else
return []
return find_occurrences(node)
When we want to find the occurrences from a given node we simply walk the tree starting at the given node until we find a leaf. Once the leaf is found we add it’s occurrences to our tally:
find_occurrences(node):
if node has occurrences:
add_to_tally(node)
for child in node:
find_occurrences(child)
Using our simple prefix tree, if we were given the search term "be" we would descend the tree until we get to the following node:
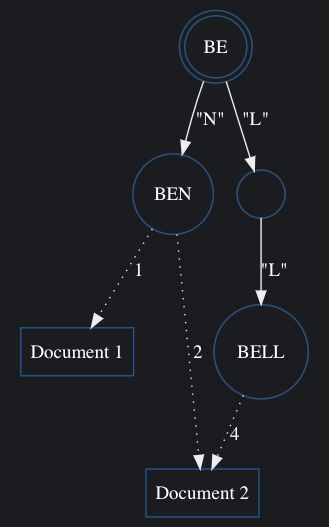
Searching for occurrences from this node, the first leaf we reach is for the word "ben" which has one occurrence in Document 1 and two occurrences in Document 2. The next leaf we encounter is for the word "bell", which has four occurrences in Document 2. This gives us the following tally:
| Document | Tally |
|---|---|
| Document 1 | 1 |
| Document 2 | 6 |
Building the results in this way allows us to quickly ascertain that words starting with the two letters "be" can be found in Document 2 primarily (there are six occurrences) and in Document 1, where we find one occurrence.
Generating the Search Data
To build the prefix tree I decided to create a GitHub action. This action would be configured to be run at a certain interval (such as every hour) to regenerate the search data.
The action performs the following steps:
- Obtain the available posts and pages from the Ghost Content API,
- The text content is extracted from the available HTML using BeautifulSoup4,
- A simple prefix tree is built for all words in the text content, and
- The data is stored in an AWS S3 bucket.
The code to perform this can be found in search/update-search.py in the repository. This script is executed periodically by the GitHub action that can be found in .github/workflows/update-search-data.yml.
Once the search tree is built, it is stored using a fairly compact data file. The file contains some summary information for the posts featured in the search data and the trie. Each field in the file that is larger than 8-bits in size is recorded as Big-Endian.
The search data starts with an unsigned 16-bit value indicating the number of posts that feature in the database. After this index follow the posts themselves. Each post comprises the following fields:
- An unsigned 16-bit giving a unique ID for the post,
- An unsigned 16-bit prefixed array of UTF-8 characters giving the title of the post, and
- An unsigned 16-bit prefixed array of UTF-8 characters giving the URL of the post.
After the documents we find the trie. Each node of the trie is encoded via a depth-first walk of the tree. For each node, we record the following fields:
- An unsigned 8-bit value representing the “key” of the trie node. This corresponds to a printable character.
- Two unsigned 16-bit values, giving: a. The number of occurrences recorded for the trie node, and b. The number of children of the node.
- Any encoded occurrences, encoded as two unsigned 16-bit values giving the ID of the post in which the term occurs and the number of times the term occurs in the document.
- The children of the node are recorded, recursively, using this structure.
Once the search data has been built and the file has been generated, the GitHub action uploads the file to AWS S3. This file can be found at:
https://s3-eu-west-1.amazonaws.com/s3.blakerain.com/data/search.bin
This data is then loaded and parsed by the search front-end.
Search Front-End
The search interface is a small amount of React code that is complied along with the customized Casper theme for the site. The interface loads and parses the search data from S3. For profiling it outputs a console message indicating how many posts and trie nodes were loaded from the search data, and the time it took:
Decoded 3 posts, 4804 term trie nodes in 6 milliseconds from 29.09 Kb
The implementation of the search interface allows a user to enter a search term. As the term is entered it is tested against the search trie, with each word tested as a prefix. The tally of matching documents is displayed as a simple list. The list is sorted by the number of occurrences, in descending order. The user can click on each link to visit the page.
When a link is clicked in the search results, the page opened. The link contains a query-string that includes the search term in a highlight key. This is detected by some JavaScript in the site theme code which uses mark.js to highlight any matching keywords.

Conclusion
I find this search implementation to be far simpler to maintain and use. We use a similar search system in our internal compliance management system at Neo. This removes the reliance on a secondary server that was solely used to service search queries. This leads to a cleaner approach that will also simplify moving the site to a CDN.
Something to note is that this search implementation – whilst very simple to implement – does have a rather heavy caveat: it only searches for prefixes. This means that if we search for the phrase "soft" we would match the word "software", but not the word "Microsoft".
As mentioned earlier, you can find all the source in the GitHub repository:

 GitHub•BlakeRain
GitHub•BlakeRain